浅析 Text and Code Embeddings by Contrastive Pre-Training
文本向量是在很多应用和文本相似度、语义搜索上有很大的应用。之前的工作通常是根据不同的应用来选择数据集定制模型架构。《Text and Code Embeddings by Contrastive Pre-Training》中展示无监督的对比学习可以获得更好的文本向量,并且在这个方法下得到的文本向量在 linear-probe 分类上达到了 SOTA(state-of-the-art),也有着很好的语义搜索能力,甚至可以与 fine-tuned 后的模型比较。

论文来自 OpenAI 的 《Text and Code Embeddings by Contrastive Pre-Training》
文本向量是在很多应用和文本相似度、语义搜索上有很大的应用。之前的工作通常是根据不同的应用来选择数据集定制模型架构。《Text and Code Embeddings by Contrastive Pre-Training》中展示无监督的对比学习可以获得更好的文本向量,并且在这个方法下得到的文本向量在 linear-probe 分类上达到了 SOTA(state-of-the-art),也有着很好的语义搜索能力,甚至可以与 fine-tuned 后的模型比较。
linear-probe 分类在七个任务下都获得了 4% - 1.8% 的提升。在 MSMARCO 数据集上提升了 23.4%、Natural Questions 上提升了 14.7%、TriviaQA 上提升了 10.6%。
这篇论文提出的方法主要是基于对比学习,训练集由成对的样本组成:
$$ (x_i,y_i) $$
x 和 y 是一个正面的样本对,表明 x 与 y 是有上下文关系或者是相似的句子对,然后组成了一个样本对集合。
$$ \{(x_i,y_i)\}^N_{i=1} $$
模型结构使用了 Transformer 结构,将句子对 \( x_i,y_i \) 的开头和结尾分别加上 \( [SOS] \) 和 \( [EOS] \) 再输入到 Encoder \( E \) 中,将模型输出[EOS]向量作为该文本的文本表征向量。
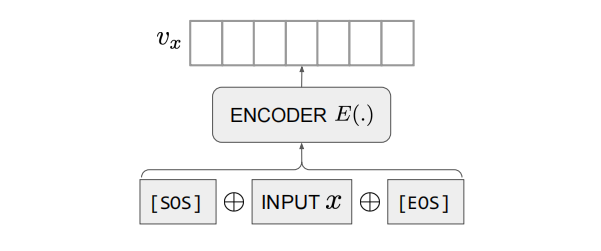
Encoder \( E \) 将输入 \( x \) 和 \( y \) 分别变成向量 \( v_x \) 和 \( v_y \) 。然后对 \( v_x \) 和 \( v_y \) 求 consine 余弦相似度。
也可以转换为下面这样。
$$\begin{align} v_x = E ( [SOS]_x \oplus x \oplus [EOS]_x ) \\ v_y = E ( [SOS]_y \oplus y \oplus [EOS]_y ) \\ sim(x,y) = \tfrac{v_x \cdot v_y}{ \| v_x \| \cdot \| v_y \| } \end{align}$$
对于一个小批次中的每个例子 \( M \),该批中的其他 \( M-1 \) 个例子都被作为 负面例子。使用批量内的负面例子可以使在 forward 和 backward 都能重复使用,提供训练的效率。
一个批次中的 logits 损失函数是一个\( M \times M \) 的矩阵,其中每个文本对的 \( logit(x_i , y_j ) \)如下:
$$ logit(x_i,y_i) = sim(x,y) \cdot exp(\tau) , \\ ∀(i,j),i,j \isin {1,2,\dots,M}$$
\( \tau \) 是一个可训练的温度函数。
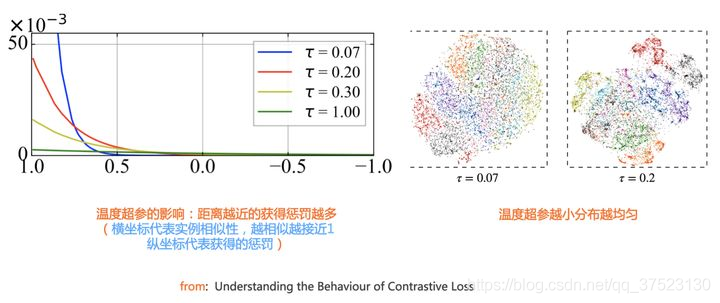
目前很多实验表明,对比学习模型要想效果比较好,温度超参 T 要设置一个比较小的值,一般设置为0.1或者0.2。
总体而言,温度参数 \( \tau \) 起到如下作用:温度参数会将模型更新到的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 \( \x_i \) 距离越近,则分配到的惩罚越多。所谓惩罚,就是在模型优化过程中,将这些负例从 \( \x_i \) 身边推开,是一种斥力。也就是说,距离 \( \x_i \) 越近的负例,温度超参会赋予更多的排斥力,将它从 \( \x_i \) 推远。而如果温度超参 \( \tau \) 设置得越小,则分配惩罚项得范围越窄,更聚焦在距离 \( \x_i \) 比较近的较小范围内的负例里。同时,这些被覆盖到的负例,因为数量少了,所以,每个负例,会承担更大的斥力。
只有矩阵对角线上的 item 才被视为正例子。最终的训练损失是行和列方向上的交叉熵损失之和。伪代码如下:
labels = np.arange(M)
l_r = cross_entropy(logits, labels, axis=0)
l_c = cross_entropy(logits, labels, axis=1)
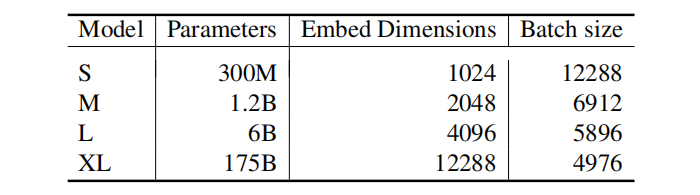
loss = (l_r + l_c) / 2论文模型采用 GPT-3 系列模型参数进行初始化,继续进行对比学习训练。并且采用了超大的批次大小,如下表所示:
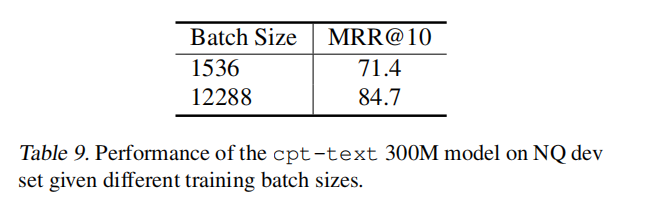
在消融实验中发现 batch_size 的确对效果有所影响,batch size 越高在对比学习下效果越好:
同样在训练过程中可以发现,训练时间越长,搜索任务效果越好而文本相似度效果越差。
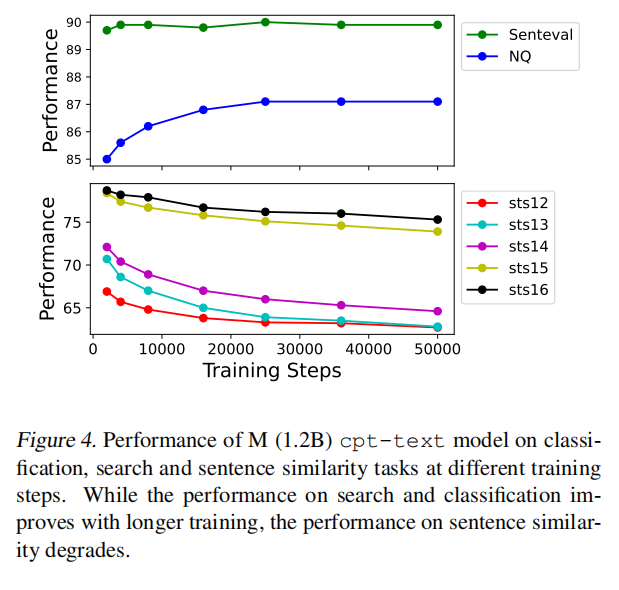
有种假设是搜索任务和相似度任务是存在冲突的,例如一个句子和它的相反含义的句子在搜索任务中应该是相关的,但是在相似任务上是不相似的。也就是说在搜索任务中,两个句子可能相关但不相似,而在相似任务中则要求两个句子必须相似。而在搜索任务下,也许相似性变得没有那么重要了。
这篇论文简单来说就是证明了:
- 相似度任务与搜索任务冲突
- Batch size 对于实际效果是有影响的
- 提出了一种对比学习的方式