知识蒸馏下两个模型的匹配程度?
现代的知识蒸馏中,我们发现学生模型可以与教师模型有着不同的预测结果,即使学生模型能完美匹配教师模型。尝试的去比较学生模型的泛化能力与匹配程度的相关性。泛化性指模型经过训练后,应用到新数据并做出准确预测的能力、匹配程度则能更好反映了学生模型蒸馏到了多少教师模型含有的知识。

知识蒸馏是现在机器学习/深度学习中一种非常流行的技术了,使用一个小的学生模型去拟合一个很大的教师模型。早在 15 年的时候《Distilling the Knowledge in a Neural Network》就已经提出了一种知识蒸馏的方法。使用一个超大的数据集进行预训练,然后将训练得到的参数放在一个小的数据集上进行微调。论文中,作者认为可以将模型看成是黑盒子,知识可以看成是输入到输出的映射关系。因此,我们可以先训练好一个 teacher 网络,然后将 teacher 的模型的输出结果 \( p \) 作为student 模型的目标,训练 student 网络,使得 student 网络的结果 \( q \) 接近 \( p \) ,因此,我们可以将损失函数写成:
$$L=CE(y,p)+aCE(q,p)$$
这里 CE 是交叉熵(Cross Entropy),y 是真实标签的 onehot 编码,q 是 teacher 模型的输出结果,p 是 student 模型的输出结果。
这篇论文证明了一个观点是:“demonstrate convincingly that the knowledge acquired by a large ensemble of models [the teacher] can be transferred to a single small model [the student]”,也就是说知识可以从大模型迁移到小模型。
但相反的是在现代的知识蒸馏中,我们发现学生模型可以与教师模型有着不同的预测结果,即使学生模型能完美匹配教师模型。比如在 self-distillation 中,学生模型是并不能与教师模型匹配,但有趣的是学生模型的泛化能力却获得了提升。当教师模型是个大模型时,匹配程度的提升会变为泛化能力的改进。
《Does Knowledge Distillation Really Work?》 尝试的去比较学生模型的泛化能力与匹配程度的相关性。泛化性指模型经过训练后,应用到新数据并做出准确预测的能力、匹配程度则能更好反映了学生模型蒸馏到了多少教师模型含有的知识。
学生模型的泛化性能和教师模型的泛化性能往往有比较大的差距,提高匹配程度可以消除学生和教师泛化性能差异而且可以提升可解释性和可依赖性。
论文中提到了主要影响匹配程度的是猜测是下面几个原因:
- 学生模型的能力比较弱;
- 模型网络结构存在很大不同;
- 蒸馏数据不足或者选择了错误的数据;
- 蒸馏过程中的优化过程有问题。
根据实验可以发现使用广泛的数据增强策略时,即使是在训练集上,学生模型的匹配度也会比较低。说明学生模型没有充分的学习训练数据。在训练集上两者的匹配度仍然会比较低可能是因为知识蒸馏的优化会收敛于次优解而不是最优,从而降低匹配度。论文验证了蒸馏匹配程度不能通过训练更长的时间或使用不同的优化器来显著提高。
To summarize, we have at last identifified a root cause of the ineffectiveness of all our previous interventions on the knowledge distillation procedure. Knowledge distillation is unable to converge to optimal student parameters, even when we know a solution and give the initialization a small head start in the direction of an optimum. Indeed, while identififiability can be an issue, in order to match the teacher on all inputs, the student has to at least match the teacher on the data used for distillation, and achieve a near-optimal value of the distillation loss. Furthermore, the suboptimal convergence of knowledge distillation appears to be a consequence of the optimization dynamics specififically, and not simply initialization bias. In practice, optimization converges to -sub-optimal solutions, leading to poor distillation fifidelity
- 我们可以知道的是学生模型的泛化性能和匹配程度的变化趋势并不一致,而匹配程度又与蒸馏的 calibration 又很大的关系。
- 知识蒸馏过程中的优化是很困难的,这也是导致低匹配度的主要原因。
- 似乎蒸馏的复杂度与数据质量之间存在某种均衡。
通过这篇论文的实验我们其实可以发现知识蒸馏肯定是有用的,它可以有效的提升模型的泛化能力,但是提升了模型泛化能力就意味着匹配能力会变弱。但是似乎反过来讲似乎不同网络结构的模型可以在牺牲泛化能力的代价下提升其匹配性或者牺牲匹配度提升泛化能力呢?比如将 Transformer 的知识蒸馏到另一个完全不同的 Transformer 上呢?
在《Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation》中其实就是这么做的。
该论文提出了一种将已有的句子嵌入编码模型扩展加入新语言支持的高效通用办法,通过该方法可使之前只支持单语言的模型转变成多语言模型。想办法尽可能将来自不同语言但句意完全等价的句子 embeding 编码映射到向量空间中同一位置,即所有语言的 embeding 共享同一个 vector space。举个栗子,就是某一个英文句子和其对应的中文翻译句子,这两个句子通过这个模型后,生成的 embeding 向量应该是尽可能是比较接近的,理想情况应该是一模一样的,这样,我们就可以通过 cos 距离或者欧式距离,来判断不同语言句子之间的相似度或是否是同一个句子。
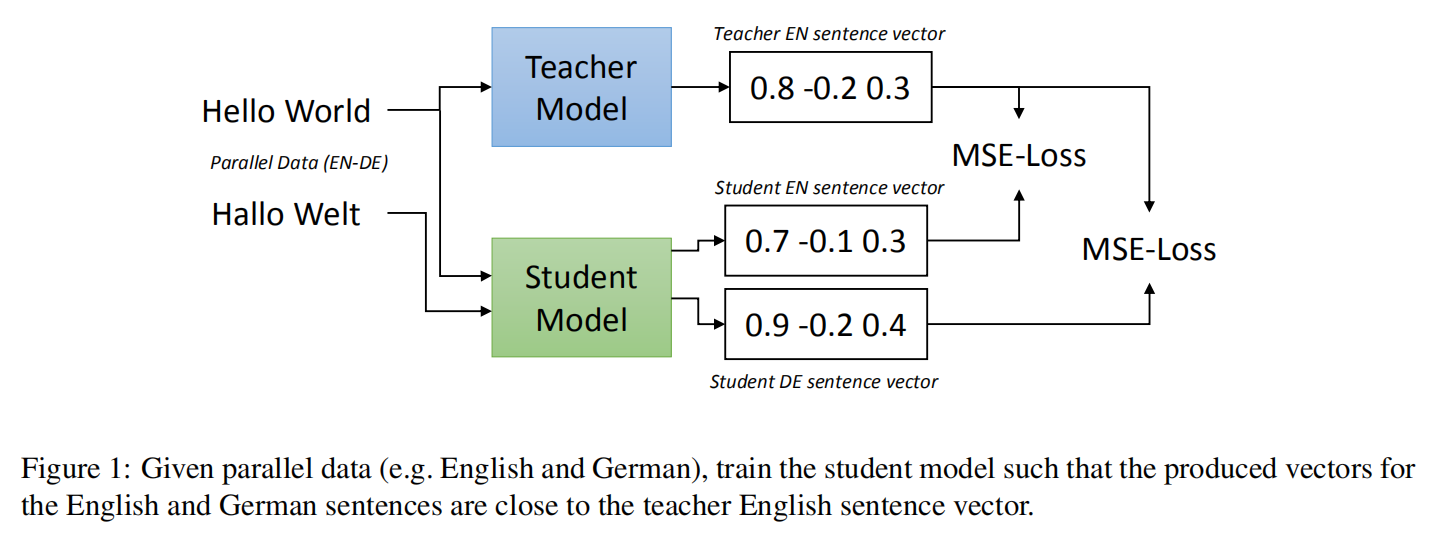
这篇论文以 Sentence BERT 作为教师模型,将 XLM-R 作为学生模型。经过多语言知识蒸馏后的模型,相似度任务下无论是在单语言测试还是在多语言测试,均达到了 SOTA 水平,胜于LASER、 mUSE 、LaBSE 这些模型。但是相反在文本检索任务却正好相反,并没有 LASER 和 LaBSE 的分数高,作者解释是 LASER 和 LaBSE 模型可以很好地识别不同语言的准确翻译,但是它在评估不是精确翻译的句子的相似性方面表现较差。也许就是上面提到的原因,匹配度高、泛化能力就低。所以蒸馏过的模型在非精准的任务上表现就会不佳,待实验...